
Building a Web Scraper in Node.js with Puppeteer
Web scraping stands out as a top method to gather data from websites. If you need to keep an eye on product prices, collect research info, or make boring online jobs easier, a web scraper can be a game-changer. This post will take a deep look at how to build a web scraper with Node.js and Puppeteer — a top choice and robust library to control headless browsers.
Once you finish this guide, you’ll know how to make your own scraper pull info from web pages, and grasp key tips to steer clear of common traps.
Ready to begin?
What is Puppeteer?
Puppeteer is a Node.js library that the Chrome DevTools team maintains. It offers a high-level API to control Chrome or Chromium through the DevTools Protocol. You can use it to:
- Create screenshots and PDFs of web pages
- Crawl and scrape websites
- Automate form submissions
- Test UI interactions
- And do much more!
Here’s the kicker: Puppeteer runs a real browser in the background. This means it can handle modern, JavaScript-heavy websites — something that gives traditional HTTP request libraries a hard time.
Getting the Project Ready
Let’s get a basic Node.js project up and running before we start building our scraper.
- Start a new Node.js project:
mkdir puppeteer-scraper
cd puppeteer-scraper
npm init -y
- Add Puppeteer to your project:
npm install puppeteer
(Heads up: Puppeteer downloads a Chromium browser that works with it. If you want to use your own Chrome instead, you can set that up .)
Creating Your First Web Scraper
Now let’s write a simple script to grab some data from a webpage.
Example: Pulling Product Prices Data From Products to Scrape
This website is great for practicing web scraping on real-world data. It’s a real e-commerce platform, so be mindful and scrape responsibly.
Make a new file and name it scrape.js:
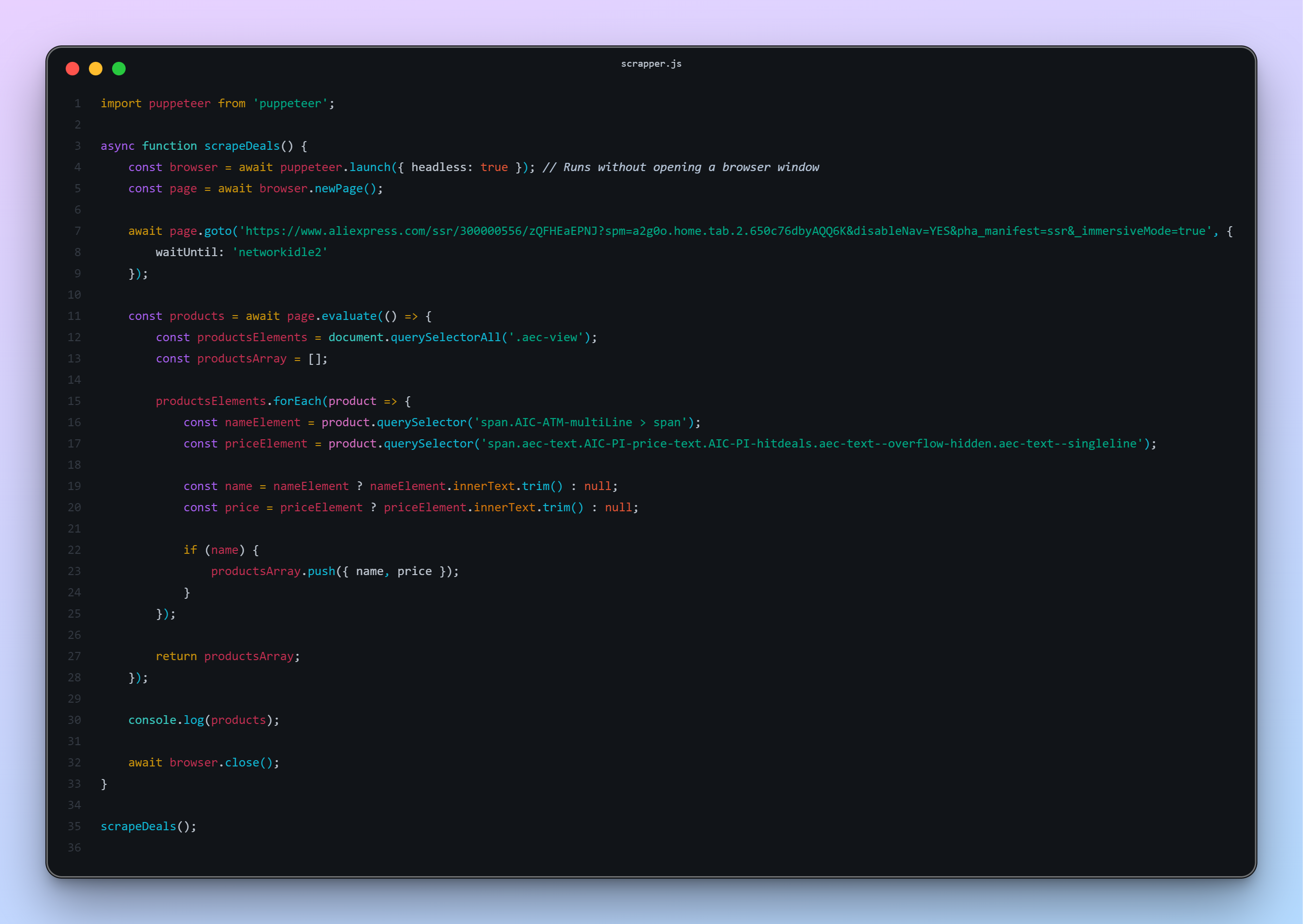
Now, run the script:
node scrape.js
Expected Output:
An array of products with their respective names and prices!
Understanding the Code
Let’s break down what’s happening:
puppeteer.launch()starts a new browser instance.browser.newPage()opens a new tab.page.goto(url)navigates to the target URL.page.evaluate()runs code inside the page’s context, allowing you to interact with the DOM and extract data.- We grab all elements with the
.aec-viewclass, extract the products name and price, and push them into an array. - Finally, we close the browser.
Best Practices for Web Scraping
While scraping is powerful, there are some important best practices to follow:
1. Respect robots.txt
Always check if a website’s robots.txt file permits scraping. Some websites explicitly disallow bots.
Example: http://example.com/robots.txt
2. Add Delays and Randomization
Instant, repeated requests can make you look suspicious. Random delays mimic human behavior.
await page.waitForTimeout(Math.floor(Math.random() * 3000)); // Wait between 0-3 seconds
3. Use a Custom User-Agent
Browsers identify themselves via the User-Agent header. Customize it to avoid being flagged as a bot.
await page.setUserAgent('Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115 Safari/537.36');
4. Handle Pagination
Many websites spread data across multiple pages. Learn how to click “Next” buttons and collect data across pages.
Example for clicking the next page:
const nextButton = await page.$('.next > a');
if (nextButton) {
await nextButton.click();
await page.waitForNavigation();
}
5. Stealth Mode
For more sophisticated scraping, you can use libraries like puppeteer-extra-plugin-stealth to make your bot even harder to detect.
npm install puppeteer-extra puppeteer-extra-plugin-stealth
const puppeteer = require('puppeteer-extra');
const StealthPlugin = require('puppeteer-extra-plugin-stealth');
puppeteer.use(StealthPlugin());
Scraping More Complex Websites
Sometimes, websites load content dynamically (infinite scrolling, lazy loading). Puppeteer allows you to handle these by:
- Waiting for elements:
await page.waitForSelector('.quote');
- Scrolling manually:
await page.evaluate(async () => {
window.scrollBy(0, window.innerHeight);
await new Promise(resolve => setTimeout(resolve, 2000)); // Wait after scrolling
});
- Clicking buttons (like “Load More”):
await page.click('.load-more-button');
Saving Scraped Data
Instead of just printing the results, you may want to save them to a file or database.
Saving to a JSON file:
const fs = require('fs');
fs.writeFileSync('quotes.json', JSON.stringify(quotes, null, 2));
Saving to a CSV file (using the papaparse library):
npm install papaparse
const Papa = require('papaparse');
const csv = Papa.unparse(quotes);
fs.writeFileSync('quotes.csv', csv);
Error Handling
When building scrapers, you’ll encounter errors like:
- Timeout errors
- Missing elements
- Network issues
Make your scraper robust with try/catch:
try {
await page.goto('http://example.com', { waitUntil: 'networkidle2', timeout: 60000 });
} catch (error) {
console.error('Navigation error:', error);
}
You can also set retries if something fails.
Puppeteer Alternatives
While Puppeteer is fantastic, you might also hear about:
- Playwright: Similar to Puppeteer but supports multiple browsers (Chrome, Firefox, WebKit).
- Cheerio: Lightweight scraping using jQuery-like syntax (only for static HTML, no JavaScript execution).
- Selenium: Great for testing and scraping across multiple programming languages.
Ethical Considerations
Web scraping exists in a legal and ethical gray area. Always:
- Respect terms of service
- Avoid overloading servers
- Give proper attribution if required
- Use APIs if available (they’re faster and safer!)
Complete Project Code
Here’s a full example project that scrapes multiple pages:
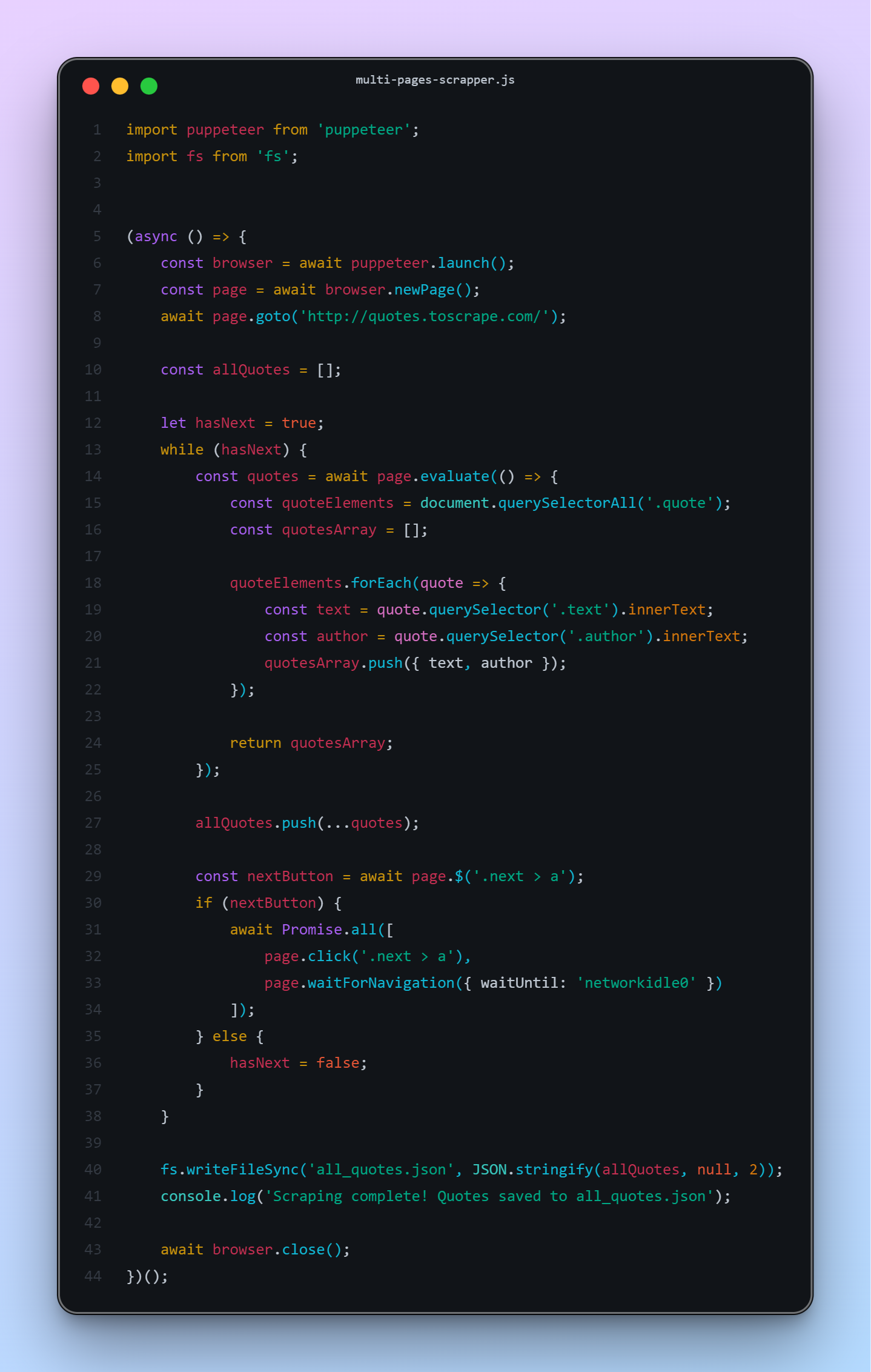
Here is the complete source code: https://github.com/WackyDawg/puppeteer-scrapper-example
Final Thoughts
Puppeteer makes web scraping in Node.js both powerful and accessible. It handles modern web pages, JavaScript-heavy content, and complex user interactions with ease. With a few best practices and ethical considerations, you can build reliable and scalable scrapers for almost any use case.
The possibilities are endless — from tracking prices to automating online tasks to gathering research data!
If you enjoyed this tutorial, stay tuned because we’ll cover more advanced Puppeteer topics like:
- Using proxies to avoid IP bans
- Capturing screenshots and PDFs
- Automating logins
- Running scrapers on a schedule (cron jobs)
Happy scraping! 🚀
Leave a comment